
Хотите более умное понимание в вашем почтовом ящике? Подпишитесь на наши еженедельные информационные бюллетени, чтобы получить только то, что имеет значение для искусственного интеллекта предприятия, данных и лидеров безопасности. Подписаться сейчас
Китайская команда гиганта электронной коммерции Alibaba QWEN сделала это снова.
Спустя всего несколько дней после выпуска бесплатного и с лицензированием с открытым исходным кодом то, что сейчас является главной неэтиализирующейся большой языковой моделью (LLM) в мире-полная остановка, даже по сравнению с проприетарными моделями ИИ из хорошо финансируемых американских лабораторий, таких как Google и Openai-в форме длинно именованных QWEN3-235B-A22507, эта группа, которые исследователи ARE выступают с другой Micle Micle Mice Mice Mice.
Это QWEN3-CODER-480B-A35B-Instruct, новая LLM с открытым исходным кодом, ориентированная на помощь в разработке программного обеспечения. Он предназначен для обработки сложных многоэтапных рабочих процессов кодирования и может создать полноценные функциональные приложения в секунды или минуты.
Модель позиционируется для конкуренции с проприетарными предложениями, такими как Claude Sonnet-4 в задачах агентского кодирования, и устанавливает новые базовые оценки среди открытых моделей.
Он доступен для обнимающего лица, GitHub, QWEN CHAT через QWEN API ALIBABA, а также растущий список сторонних платформ кодирования атмосфера и инструментов ИИ.
Лицензирование с открытым исходным газом означает низкую стоимость и высокую опциону для предприятий
Но в отличие от Claude и других проприетарных моделей, QWEN3-Coder, который мы будем на короткое время, теперь доступен в рамках лицензии Apache 2.0 с открытым исходным кодом, что означает, что любое предприятие бесплатно брать на себя, загружать, модифицировать, развернуть и использовать в своих коммерческих приложениях для сотрудников или конечных клиентов без оплаты Alibaba или кого-либо еще.
Он также так высокопроизводительна для сторонних критериев и анекдотического использования среди пользователей ИИ для «кодирования вибрации», используя естественный язык и без формальных процессов разработки и шагов. По крайней мере, один исследователь LLM, Себастьян Рашка, опубликовано на x: «Это может быть лучшей моделью кодирования.
Разработчики и предприятия, заинтересованные в его загрузке, могут найти код в репозитории обнимания кода ИИ.
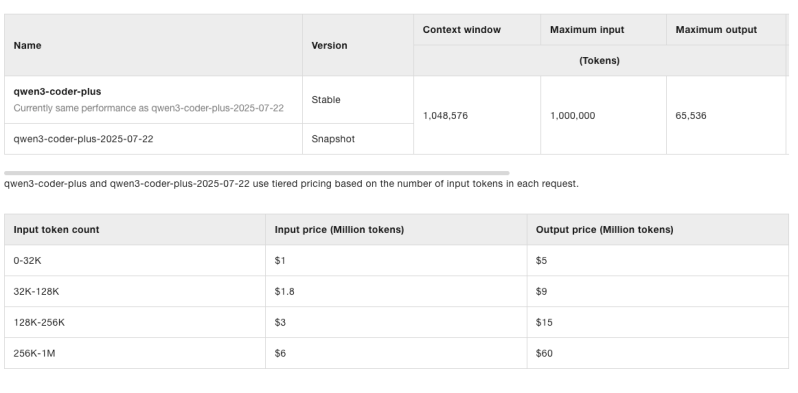
Предприятия, которые не хотят или не имеют возможности размещать модель самостоятельно или через различных сторонних поставщиков облачных выводов, также могут использовать ее непосредственно через API Alibaba Cloud QWEN, где затраты на токен на за миллион начинается с 1 доллара США за миллион. 6 долларов США/60 долларов за полный миллион.

Модельная архитектура и возможности
Согласно документации, опубликованной командой QWEN Online, QWEN3-Coder представляет собой модель смеси экспертов (MOE) с 480 миллиардами общего количества параметров, 35 миллиардов активности на запрос и 8 активных экспертов из 160.
Он поддерживает длину контекста токена 256 тыс. Назначительно с экстраполяцией до 1 миллиона токенов с использованием пряжи (еще одна экстраполяция веревки) — метод, используемый для расширения длины контекста языковой модели за пределами его первоначального ограничения обучения путем изменения вращающихся позиционных встроений (веревка), используемой во время вычисления внимания. Эта емкость позволяет модели понимать и манипулировать целыми репозиториями или длинными документами за один проход.
Разработанный в качестве модели причинно-следственного языка, он имеет 62 слоя, 96 головок внимания для запросов и 8 для пар клавишных значений. Он оптимизирован для токеновых, подходящих для инструкций задач и опускает поддержку для блоков
Высокая производительность
QWEN3-Coder достиг ведущей производительности среди открытых моделей на нескольких агентских оценках:
- Swe-Bench подтвержден: 67,0% (стандарт), 69,6% (500-летний)
- GPT-4.1: 54,6%
- Предварительный просмотр Gemini 2.5 Pro: 49,0%
- Claude Sonnet-4: 70,4%
Модель также конкурентно оценивает такие задачи, как использование агентских браузеров, многоязычное программирование и использование инструментов. Визуальные тесты показывают прогрессивное улучшение между итерациями обучения в таких категориях, как генерация кода, программирование SQL, редактирование кода и следующие инструкции.
Параметры инструментов и интеграции
Наряду с моделью, QWEN имеет QWEN Code с открытым исходным кодом, инструмент CLI, разбросанный из кода Gemini. Этот интерфейс поддерживает вызов функций и структурированные подсказки, что облегчает интеграцию QWEN3-Coder в кодирование рабочих процессов. Код QWEN поддерживает среды node.js и может быть установлен через NPM или из источника.
QWEN3-Coder также интегрируется с такими платформами разработчиков, как:
- Claude Code (через прокси -сервер Dashscope или настройку маршрутизатора)
- Клайн (как открытый бэкэнд)
- Ollama, Lmstudio, Mlx-LM, Llama.cpp и Ktransformers
Разработчики могут запускать QWEN3-Coder локально или подключаться через API-совместимые с OpenAI, используя конечные точки, размещенные в Alibaba Cloud.
Методы после тренировки: код RL и Планирование длинного хоризона
В дополнение к предварительной подготовке на 7,5 триллиона токена (70% кода), QWEN3-Coder выигрывает от передовых методов после тренировки:
- Code RL (подкрепление обучения): подчеркивает высококачественное обучение, ориентированное на выполнение на различные, проверенные задачи кода;
- Агент Long-Horizon RL: обучает модель планировать, использовать инструменты и адаптироваться к многообразовательным взаимодействиям.
Этот этап имитирует реальные проблемы разработки программного обеспечения. Чтобы включить это, QWEN построил систему в размере 20 000 средств в облаке Alibaba, предлагая масштаб, необходимую для оценки и обучения моделей на сложных рабочих процессах, подобных тем, которые встречаются в Swe-Bench.
Последствия предприятия: ИИ для инженерных и рабочих процессов DevOps
Для предприятий QWEN3-Coder предлагает открытую, очень способную альтернативу проприетарным моделям с закрытым исходным кодом. При высоких результатах в выполнении кодирования и рассуждениях о длинном контексте, это особенно актуально для:
- Понимание на уровне кодовой базы: Идеально подходит для систем искусственного интеллекта, которые должны понимать большие репозитории, техническую документацию или архитектурные модели.
- Автоматизированные рабочие процессы запроса на вытягивание: Его способность планировать и адаптироваться по очереди делает его подходящим для автоматического генерации или просмотра запросов на тягу.
- Интеграция инструмента и оркестровка: Через свой собственный интерфейс API-интерфейс и функциональный интерфейс, модель может быть встроена во внутренние инструменты и системы CI/CD. Это делает его особенно жизнеспособным для агентских рабочих процессов и продуктов, или для тех, где пользователь вызывает одну или несколько задач, которые он хочет, чтобы модель ИИ снялась и делала автономно, сама по себе проверяя только после того, как заканчивается или когда возникают вопросы.
- Данные резидентуры и контроль затрат: В качестве открытой модели предприятия могут развернуть QWEN3-Coder на своей собственной инфраструктуре-будь то облачный или на племен-избегать блокировки поставщиков и более напрямую управление вычислительным использованием.
Поддержка длинных контекстов и вариантов развертывания модульного развертывания в различных средах разработчиков делает QWEN3-Coder кандидатом на производственные трубопроводы AI как в крупных технологических компаниях, так и в небольших инженерных командах.
Доступ к разработчику и лучшие практики
Чтобы оптимально использовать QWEN3-Coder, QWEN рекомендует:
- Настройки отбора проб: температура = 0,7, TOP_P = 0,8, TOP_K = 20, Repetition_penalty = 1,05
- Длина вывода: до 65 536 токенов
- Версия трансформаторов: 4.51.0 или более поздней версии (более старые версии могут бросить ошибки из -за несовместимости QWEN3_MOE)
Примеры API и SDK предоставляются с использованием CopenAI-совместимых клиентов Python.
Разработчики могут определять пользовательские инструменты и позволить QWEN3-Coder динамически вызывать их во время разговоров или задач генерации кода.
Теплый ранний прием от пользователей Power Power
Первоначальные ответы на QWEN3-CODER-480B-A35B-объект были заметно положительными среди исследователей ИИ, инженеров и разработчиков, которые протестировали модель в реальных рабочих процессах кодирования.
В дополнение к высокой похвале Рашки, Wolfram Ravenwolf, инженера и оценщика ИИ в Ellamindai, поделился своим опытом, интегрируя модель с Claude Code на X, заявив: «Это, безусловно, лучший в настоящее время».
После тестирования нескольких интеграционных прокси, Ravenwolf сказал, что в конечном итоге он создал свой собственный, используя Litellm для обеспечения оптимальной производительности, демонстрируя привлекательность модели для практических практикующих, ориентированных на настройку инструментов.
Педагог и Tinkerer Ai Кевин Нельсон также взвесили X после использования модели для задач моделирования.
«Qwen 3 Coder находится на другом уровне», Он опубликовал, отметив, что модель не только выполнялась на предоставленных лесах, но даже внедрила сообщение в выходные данные симуляции — неожиданный, но желанный признак осознания модели о контексте задачи.
Даже соучредитель Twitter и основатель Square (теперь называемый «Block») Джек Дорси опубликовал сообщение X в похвале модели: «Goose + qwen3-coder = вау,«В связи с блок -с открытым исходным исходным ИИ Framework Goose.
Эти ответы предполагают, что QWEN3-Coder резонирует с технически подкованной базой пользователей, ищущей производительность, адаптивность и более глубокую интеграцию с существующими стеками разработки.
Заглядывая в будущее: больше размеров, больше вариантов использования
В то время как этот релиз фокусируется на самом мощном варианте, QWEN3-CODER-480B-A35B-объект, команда QWEN указывает, что дополнительные размеры модели находятся в разработке.
Они будут направлены на то, чтобы предложить аналогичные возможности с более низкими затратами на развертывание, расширяя доступность.
Будущая работа также включает в себя изучение самосовершенствования, поскольку команда исследует, могут ли агентские модели итеративно усовершенствовать свои собственные результаты с помощью реального использования.
Источник